Performance
Introduction
In the ever-evolving landscape of the API economy, time emerges as one of our most precious resources. Swift response times have become essential for both API providers and consumers. As providers strive to meet response time percentiles, consumers are becoming more aware of these metrics, often establishing service level agreements (SLAs) based on them.
At Lunar, we recognize the significance of latency. Our solution addresses the complex challenges of API consumption by by acting as a bridge between API providers and consumers. Naturally, we aim to minimize any impact on our users' existing latency. As developers, we knew instinctively that this is precisely what we would desire as end users.
To achieve nearly invisible latency footprint, extensive research went into selecting the ideal stack and architecture. However, any assumption must undergo rigorous testing to validate its accuracy. This is where latency benchmarking becomes invaluable.
Lunar's Performance Footprint
As declared in our Architecture page, Lunar operates alongside our users' applications, handling all outgoing traffic directed towards third-party providers. While its default behavior involves seamless forwarding of requests and responses, akin to forward proxies, its true brilliance materializes when augmented with flows, these flows can modify requests and responses, enabling Lunar to cache responses, short-circuit requests, or even diagnose issues. This flexibility allows Lunar to adapt to a wide range of use cases, from optimizing API calls to troubleshooting network issues.
Our Benchmarks
Latency Footprint
Through our benchmarking sessions, we wanted to unveil Lunar's latency footprint on response time percentiles in comparison to direct API calls made without Lunar's intervention. In our experiments, we have selected a provider with a constant response time of 150ms, which is relatively fast for a web-based API.
To accomplish this, we explore the following scenarios:
- Traffic passes directly to the API provider without any intermediary. (referred to as "direct")
- Traffic passes through Lunar without any flows enabled, acting as a simple proxy. (referred to as "no-flow")
- Traffic passes through Lunar while employing a simple flow that doesn't short circuit requests. (referred to as "with-active-flow")
We allocated three different AWS EC2 instances of type c4a.large for this purpose - one for the client application making API requests, one dedicated to Lunar, and another one dedicated to the API provider.
Setup
We used Apache AB, to simulate client-side behavior and gather necessary metrics. To replicate how client applications interact with Lunar, we directed Apache AB to call Lunar, which, in turn, forwarded the requests to the Provider.
On the provider side, we leveraged go-httpbin, a Docker image that serves as a Go version of httpbin.org.
Benchmark Results
In our performance analysis, we conducted three experiments to compare the following scenarios:
- Calls directly to the provider (referred to as "direct").
- Calls to the provider via Lunar Proxy without any active flow (referred to as "no-flow").
- Calls to the provider via Lunar Proxy with an active flow (referred to as "with-active-flow").
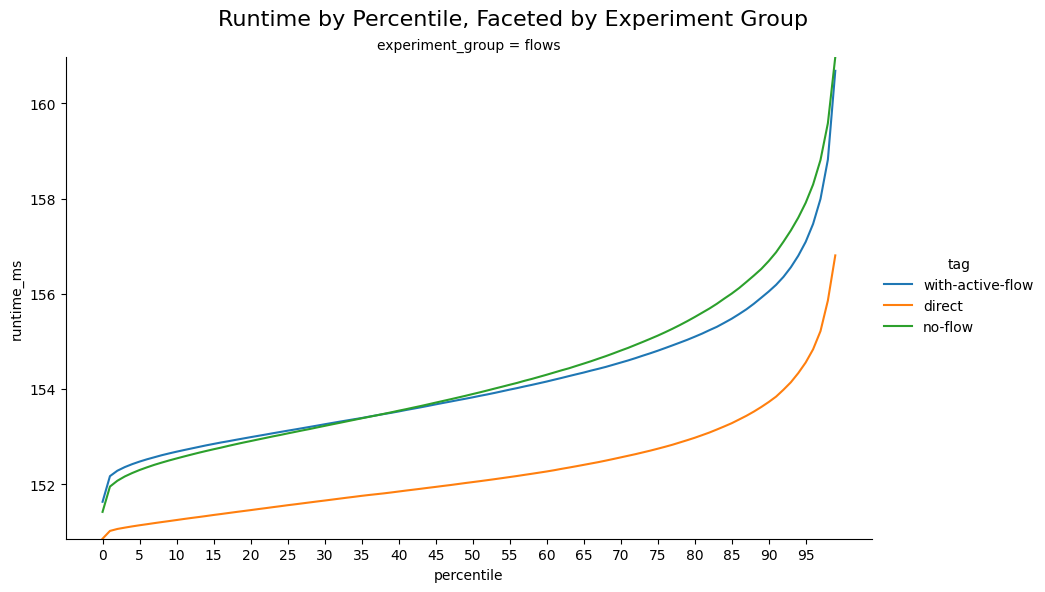
The visualization below presents percentile values on the X-axis and runtime in milliseconds on the Y-axis, highlighting the differences between each experiment and the baseline direct experiment, which are relatively small across percentiles.
To provide a clearer understanding, let's examine the same graph with the Y-axis representing the delta from the baseline for each experiment and percentile. In the direct experiment, the delta remains 0 for all percentiles, as it is compared against itself.
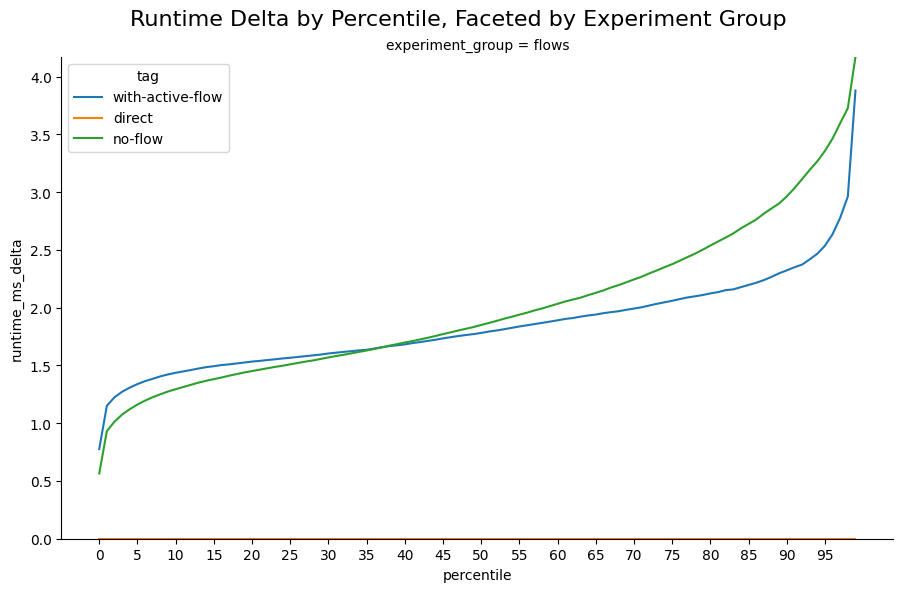
- At the 99th percentile, Lunar Proxy adds around 4ms (with no flow and with an active flow) to the overall response time of HTTP calls.
Capacity Benchmark
Through our benchmarking sessions, we aimed to assess the capacity of Lunar in handling requests per second under various load conditions. In this performance evaluation, we established an EKS cluster and node group with the provided hardware configuration, ensuring a reliable and scalable infrastructure. Employing our benchmarking tool, we generated a load on the Lunar to measure its performance within the EKS cluster. By systematically varying load parameters, including the number of concurrent connections and request rate, we sought to understand how Lunar performed under different scenarios.
Our objective was to uncover the efficiency and capability of Lunar, identifying potential bottlenecks or areas for improvement in its capacity to handle substantial workloads.
Benchmark Results
The results demonstrate the requests per second achieved by Lunar in each scenario, providing insights into its performance characteristics. With multiple requests ranging from 32 to 256, and capacity limits from 1 to 8 cores, we observed a clear correlation between these factors and the resulting requests per second. These findings contribute to a deeper understanding of Lunar's performance and can assist in optimizing its configuration for enhanced capacity and throughput.
| Concurrency | Capacity Limit (Cores) | Number of Requests | Requests per Second |
|---|---|---|---|
| 32 | 1 | 2,500,000 | 9,050.42 |
| 64 | 2 | 5,000,000 | 16,550.48 |
| 128 | 4 | 10,000,000 | 35,896.17 |
| 256 | 8 | 20,000,000 | 84,867.79 |
In this table, the columns represents the following:
- Concurrency: The number of multiple requests made at a time (concurrency).
- Capacity Limit (Cores): The specified limit on the number of cores for Lunar's capacity.
- Number of Requests: The total number of requests performed in the benchmark.
- Requests per Second: The average number of requests processed per second Lunar's Proxy can handle.
Summary
Through extensive benchmarking, Lunar demonstrates impressive results. It adds only a small latency footprint to response times, around 4ms at the 99th percentile. The capacity benchmark shows that Lunar efficiently handles substantial workloads, achieving up to 84,867 requests per second. These outstanding results validate Lunar's effectiveness in minimizing latency and ensuring optimal performance in API interactions.