Custom API Quota Management
Custom API Quota Management enables dynamic quota allocation based on custom properties of API calls.
Unlike other quotas which count the number of transactions made to an API provider, custom-quota allows you to define custom counters/metrics you wish to base your quota limits on.
Scenarios
1. Quota Management Based on LLM Tokens
Instead of limiting by the number of requests to a Large Language Model (LLM) API, define a quota based on the total number of tokens used in the requests. This allows for more granular control over consumption, especially when requests vary significantly in token count. Configure Lunar.dev to track the prompt_tokens and completion_tokens in the API response and enforce limits on their sum. This ensures you stay within your allocated token budget.
2. Quota Management Based on Google Maps Elements
For the Google Maps Distance Matrix API, manage quota based on the number of "elements" in the request (combinations of origins and destinations). Lunar.dev can extract the number of origins and destinations from the request body. Set up a custom quota that multiplies these values to represent the elements, allowing you to control spending based on the complexity of the routing queries. This prevents unexpected cost overruns due to large matrix calculations.
3. Quota Management Based on Data Transfer Size
Control API consumption based on the volume of data transferred. For APIs where data transfer is a significant cost factor, configure a custom quota that monitors the Content-Length header in the response. Set limits on the total bytes downloaded within a specific timeframe. This is particularly useful for services like cloud storage or data analytics platforms where large data payloads are common, helping to optimize bandwidth usage and prevent exceeding transfer limits.
Example: OpenAI - custom quota based on tokens
quotas:
- id: GPT-4o-mini-quota
filter:
url: api.openai.com/v1/chat/completions
headers:
- key: x-lunar-custom-model
value: gpt-4o-mini
strategy:
custom_counters:
values:
- value_name: estimated
value_path: request.headers.x-lunar-estimated-tokens
- value_name: completion_tokens
value_path: response.body.usage.completion_tokens
- value_name: prompt_tokens
value_path: response.body.usage.prompt_tokens
operations:
request: "quota = quota + estimated"
response: "quota = (quota - estimated) + completion_tokens + prompt_tokens"
max: 40000
interval: 1
interval_unit: minute
Advanced example
We can also combine custom quota with other quotas to cover more complex use cases
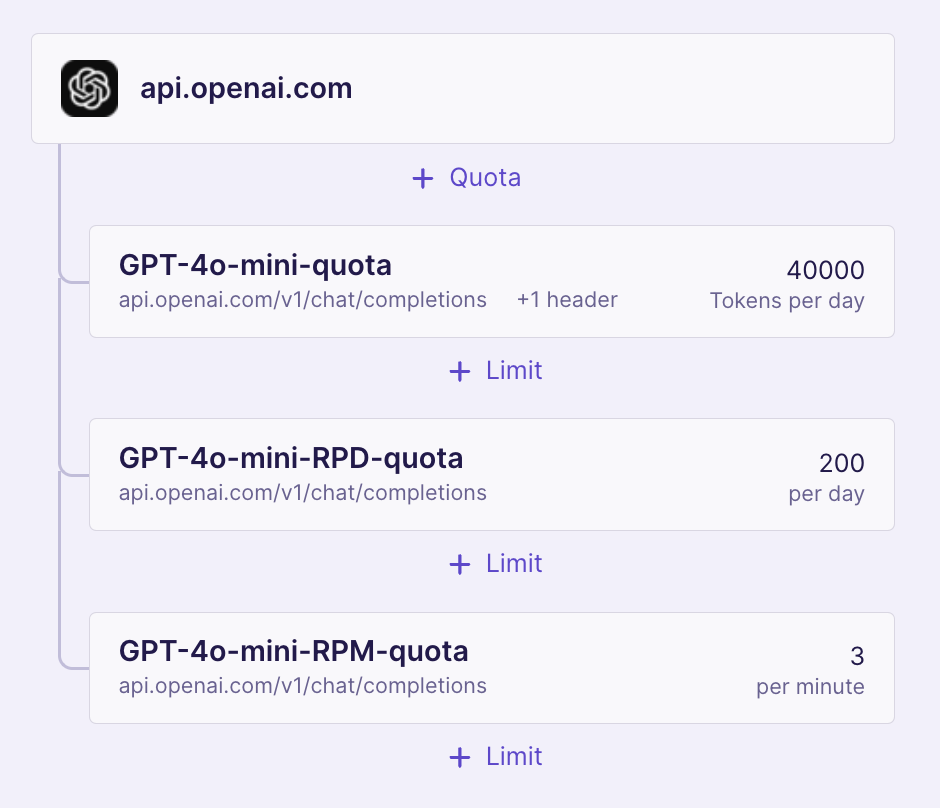
quotas:
- id: GPT-4o-mini-token-quota
filter:
url: api.openai.com/v1/chat/completions
headers:
- key: x-Lunar-custom-model
value: gpt-4o-mini
strategy:
custom_counters:
- name: estimated
count: request.headers.x-lunar-estimated-tokens
- name: completion_tokens
count: response.body.usage.completion_tokens
- name: prompt_tokens
count: response.body.usage.prompt_tokens
max: 40000
interval: 1
interval_unit: minute
- id: GPT-4o-mini-RPD-quota
parent_id: GPT-4o-mini-token-quota
strategy:
fixed_window:
max: 200
interval: 1
interval_unit: day
- id: GPT-4o-mini-RPM-quota
parent_id: GPT-4o-mini-RPD-quota
strategy:
fixed_window:
max: 3
interval: 1
interval_unit: minute